Building a GraphQL API with EdgeDB and Strawberry
EdgeDB allows you to query your database with GraphQL via the built-in GraphQL extension. It enables you to expose GraphQL-driven CRUD APIs for all object types, their properties, links, and aliases. This opens up the scope for creating backend-less applications where the users will directly communicate with the database. You can learn more about that in the GraphQL section of the docs.
However, as of now, EdgeDB is not ready to be used as a standalone backend. You shouldn’t expose your EdgeDB instance directly to the application’s frontend; this is insecure and will give all users full read/write access to your database. So, in this tutorial, we’ll see how you can quickly create a simple GraphQL API without using the built-in extension, which will give the users restricted access to the database schema. Also, we’ll implement HTTP basic authentication and demonstrate how you can write your own GraphQL validators and resolvers. This tutorial assumes you’re already familiar with GraphQL terms like schema, query, mutation, resolver, validator, etc, and have used GraphQL with some other technology before.
We’ll build the same movie organization system that we used in the Flask tutorial and expose the objects and relationships as a GraphQL API. Using the GraphQL interface, you’ll be able to fetch, create, update, and delete movie and actor objects in the database. Strawberry is a Python library that takes a code-first approach where you’ll write your object schema as Python classes. This allows us to focus more on how you can integrate EdgeDB into your workflow and less on the idiosyncrasies of GraphQL itself. We’ll also use the EdgeDB client to communicate with the database, FastAPI to build the authentication layer, and Uvicorn as the webserver.
Prerequisites
Before we start, make sure you have installed the
edgedb command-line tool. Here, we’ll use Python 3.10 and a few of its
latest features while building the APIs. A working version of this tutorial can
be found on Github.
Install the dependencies
To follow along, clone the repository and head over to the strawberry-gql
directory.
$
git clone git@github.com:edgedb/edgedb-examples.git$
cd edgedb-examples/strawberry-gqlCreate a Python 3.10 virtual environment, activate it, and install the dependencies with this command:
$
python3.10 -m venv .venv$
source .venv/bin/activate$
pip install edgedb fastapi strawberry-graphql uvicorn[standard]Initialize the database
Now, let’s initialize an EdgeDB project. From the project’s root directory:
$
edgedb project initInitializing project... Specify the name of EdgeDB instance to use with this project [default: strawberry_crud]: > strawberry_crud Do you want to start instance automatically on login? [y/n] > y Checking EdgeDB versions...
Once you’ve answered the prompts, a new EdgeDB instance called
strawberry_crud will be created and started.
Connect to the database
Let’s test that we can connect to the newly started instance. To do so, run:
$
edgedbYou should be connected to the database instance and able to see a prompt similar to this:
EdgeDB 2.x (repl 2.x)
Type \help for help, \quit to quit.
edgedb>You can start writing queries here. However, the database is currently empty. Let’s start designing the data model.
Schema design
The movie organization system will have two object types—movies and actors. Each movie can have links to multiple actors. The goal is to create a GraphQL API suite that’ll allow us to fetch, create, update, and delete the objects while maintaining their relationships.
EdgeDB allows us to declaratively define the structure of the objects. The
schema lives inside .esdl file in the dbschema directory. It’s
common to declare the entire schema in a single file dbschema/default.esdl.
This is how our datatypes look:
# dbschema/default.esdl
module default {
abstract type Auditable {
property created_at -> datetime {
readonly := true;
default := datetime_current();
}
}
type Actor extending Auditable {
required property name -> str {
constraint max_len_value(50);
}
property age -> int16 {
constraint min_value(0);
constraint max_value(100);
}
property height -> int16 {
constraint min_value(0);
constraint max_value(300);
}
}
type Movie extending Auditable {
required property name -> str {
constraint max_len_value(50);
}
property year -> int16{
constraint min_value(1850);
};
multi link actors -> Actor;
}
}Here, we’ve defined an abstract type called Auditable to take advantage
of EdgeDB’s schema mixin system. This allows us to add a created_at
property to multiple types without repeating ourselves.
The Actor type extends Auditable and inherits the created_at
property as a result. This property is auto-filled via the datetime_current
function. Along with the inherited type, the actor type also defines a few
additional properties like called name, age, and height. The
constraints on the properties make sure that actor names can’t be longer than
50 characters, age must be between 0 to 100 years, and finally, height must be
between 0 to 300 centimeters.
We also define a Movie type that extends the Auditable abstract type.
It also contains some additional concrete properties and links: name,
year, and an optional multi-link called actors which refers to the
Actor objects.
Build the GraphQL API
The API endpoints are defined in the app directory. The directory structure
looks as follows:
app
├── __init__.py
├── main.py
└── schemas.pyThe schemas.py module contains the code that defines the GraphQL schema and
builds the queries and mutations for Actor and Movie objects. The
main.py module then registers the GraphQL schema, adds the authentication
layer, and exposes the API to the webserver.
Write the GraphQL schema
Along with the database schema, to expose EdgeDB’s object relational model as a
GraphQL API, you’ll also have to define a GraphQL schema that mirrors the
object structure in the database. Strawberry allows us to express this schema
via type annotated Python classes. We define the Strawberry schema in the
schema.py file as follows:
# strawberry-gql/app/schema.py
from __future__ import annotations
import json # will be used later for serialization
import edgedb
import strawberry
client = edgedb.create_async_client()
@strawberry.type
class Actor:
name: str | None
age: int | None = None
height: int | None = None
@strawberry.type
class Movie:
name: str | None
year: int | None = None
actors: list[Actor] | None = NoneHere, the GraphQL schema mimics our database schema. Similar to the Actor
and Movie types in the EdgeDB schema, here, both the Actor and
Movie models have three attributes. Likewise, the actors attribute in
the Movie model represents the link between movies and actors.
Query actors
In this section, we’ll write the resolver to create the queries that’ll
allow us to fetch the actor objects from the database. You’ll need to write the
query resolvers as methods in a class decorated with the @strawberry.type
decorator. Each method will also need to be decorated with the
@strawberry.field decorator to mark them as resolvers. Resolvers can be
either sync or async. In this particular case, we’ll write asynchronous
resolvers that’ll act in a non-blocking manner. The query to fetch the actors
is built in the schema.py file as follows:
# strawberry-gql/app/schema.py
...
@strawberry.type
class Query:
@strawberry.field
async def get_actors(
self, filter_name: str | None = None
) -> list[Actor]:
if filter_name:
actors_json = await client.query_json(
"""
select Actor {name, age, height}
filter .name=<str>$filter_name
""",
filter_name=filter_name,
)
else:
actors_json = await client.query_json(
"""
select Actor {name, age, height}
"""
)
actors = json.loads(actors_json)
return [
Actor(name, age, height)
for (name, age, height) in (
d.values() for d in actors
)
]
# Register the Query.
schema = strawberry.Schema(query=Query)Here, the get_actors resolver method accepts an optional filter_name
parameter and returns a list of Actor type objects. The optional
filter_name parameter allows us to build the capability of filtering the
actor objects by name. Inside the method, we use the EdgeDB client to
asynchronously query the data. The client.query_json method returns JSON
serialized data which we use to create the Actor instances. Finally, we
return the list of actor instances and the rest of the work is done by
Strawberry. Then in the last line of the above snippet, we register the
Query class to build the Schema instance.
Afterward, in the main.py module, we use FastAPI to expose the /graphql
endpoint. Also, we add a basic HTTP authentication layer to demonstrate how you
can easily protect your GraphQL endpoint by leveraging FastAPI’s dependency
injection system. Here’s how the content of the main.py looks:
# strawberry-gql/app/main.py
from __future__ import annotations
import secrets
from typing import Literal
from fastapi import (
Depends, FastAPI, HTTPException, Request,
Response, status
)
from fastapi.security import HTTPBasic, HTTPBasicCredentials
from strawberry.fastapi import GraphQLRouter
from app.schema import schema
app = FastAPI()
router = GraphQLRouter(schema)
security = HTTPBasic()
def auth(
credentials: HTTPBasicCredentials = Depends(security)
) -> Literal[True]:
"""Simple HTTP Basic Auth."""
correct_username = secrets.compare_digest(
credentials.username, "ubuntu"
)
correct_password = secrets.compare_digest(
credentials.password, "debian"
)
if not (correct_username and correct_password):
raise HTTPException(
status_code=status.HTTP_401_UNAUTHORIZED,
detail="Incorrect email or password",
headers={"WWW-Authenticate": "Basic"},
)
return True
@router.api_route("/", methods=["GET", "POST"])
async def graphql(request: Request) -> Response:
return await router.handle_graphql(request=request)
app.include_router(
router, prefix="/graphql", dependencies=[Depends(auth)]
)First, we initialize the FastAPI app instance which will communicate with
the Uvicorn webserver. Then we attach the initialized schema instance to
the GraphQLRouter. The HTTPBasic class provides the machinery required
to add the authentication layer. The auth function houses the
implementation details of how we’re comparing the incoming and expected
username and passwords as well as how the webserver is going to handle
unauthorized requests. The graphql handler function is the one that handles
the incoming HTTP requests. Finally, the router instance and the security
handler are registered to the app instance via the app.include_router
method.
We can now start querying the /graphql endpoint. We’ll use the built-in
GraphiQL interface to perform the queries. Before that, let’s start the Uvicorn
webserver first. Run:
$
uvicorn app.main:app --port 5000 --reloadThis exposes the webserver in port 5000. Now, in your browser, go to http://localhost:5000/graphql. Here, you’ll find that the HTTP basic auth requires us to provide the username and password.
Currently, the allowed username and password is ubuntu and debian
respectively. Provide the credentials and you’ll be taken to a page that looks
like this:
You can write your GraphQL queries here. Let’s write a query that’ll fetch all the actors in the database and show all three of their attributes. The following query does that:
query ActorQuery {
getActors {
age
height
name
}
}The following response will appear on the right panel of the GraphiQL explorer:
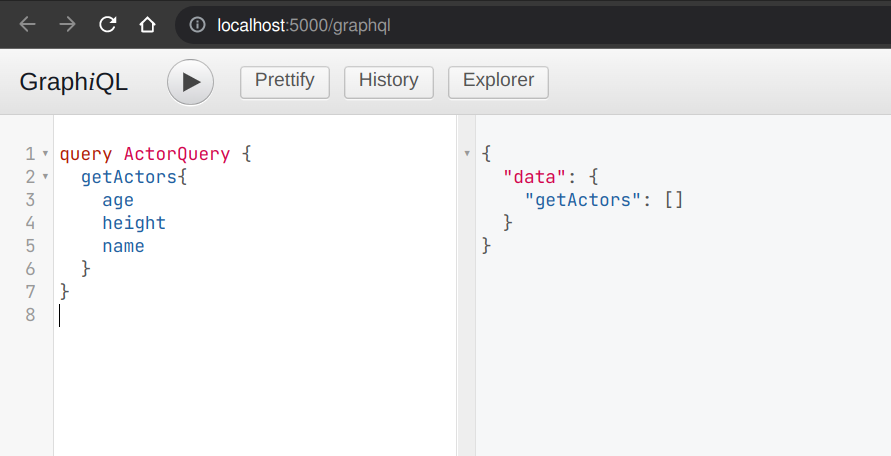
Since as of now, the database doesn’t have any data, the payload is returning an empty list. Let’s write a mutation and create some actors.
Mutate actors
Mutations are also written in the schema.py file. To write a mutation,
you’ll have to create a separate class where you’ll write the mutation
resolvers. The resolver methods will need to be decorated with
the @strawberry.mutation decorator. You can write the mutation that’ll
create an actor object in the database as follows:
# strawberry-gql/app/schema.py
...
@strawberry.type
class Mutation:
@strawberry.mutation
async def create_actor(
self, name: str,
age: int | None = None,
height: int | None = None
) -> ResponseActor:
actor_json = await client.query_single_json(
"""
with new_actor := (
insert Actor {
name := <str>$name,
age := <optional int16>$age,
height := <optional int16>$height
}
)
select new_actor {name, age, height}
""",
name=name,
age=age,
height=height,
)
actor = json.loads(actor_json)
return Actor(
actor.get("name"),
actor.get("age"),
actor.get("height")
)
# Mutation class needs to be registered here.
schema = strawberry.Schema(query=Query, mutation=Mutation)Creating a mutation also includes data validation. By type annotating the
Mutation class, we’re implicitly asking Strawberry to perform data
validation on the incoming request payload. Strawberry will raise an HTTP 400
error if the validation fails. Let’s create an actor. Submit the following
GraphQL query in the GraphiQL interface:
mutation ActorMutation {
__typename
createActor(
name: "Robert Downey Jr.",
age: 57,
height: 173
) {
age
height
name
}
}In the above mutation, name is a required field and the remaining two are
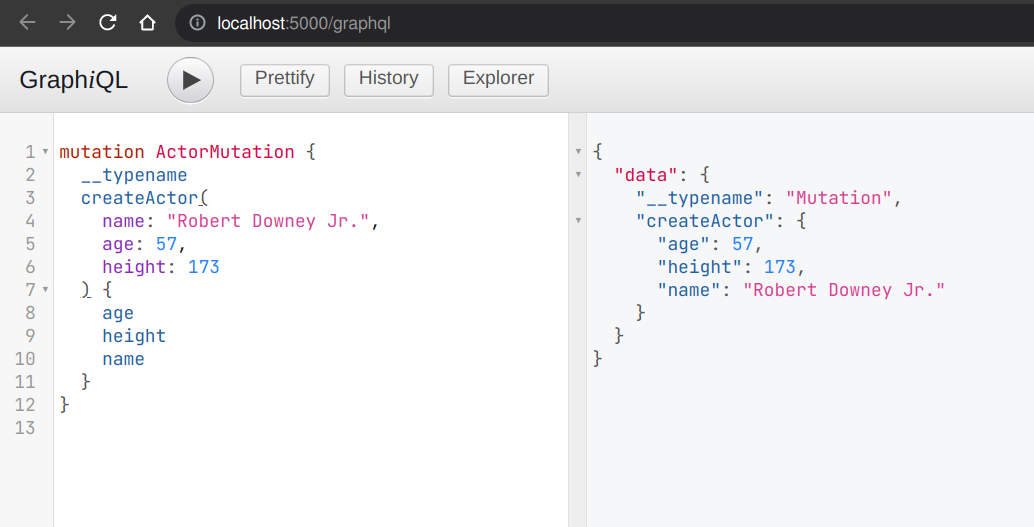
optional fields. This mutation will create an actor named Robert Downey Jr.
and show all three attributes— name, age, and height of the created
actor in the response payload. Here’s the response:
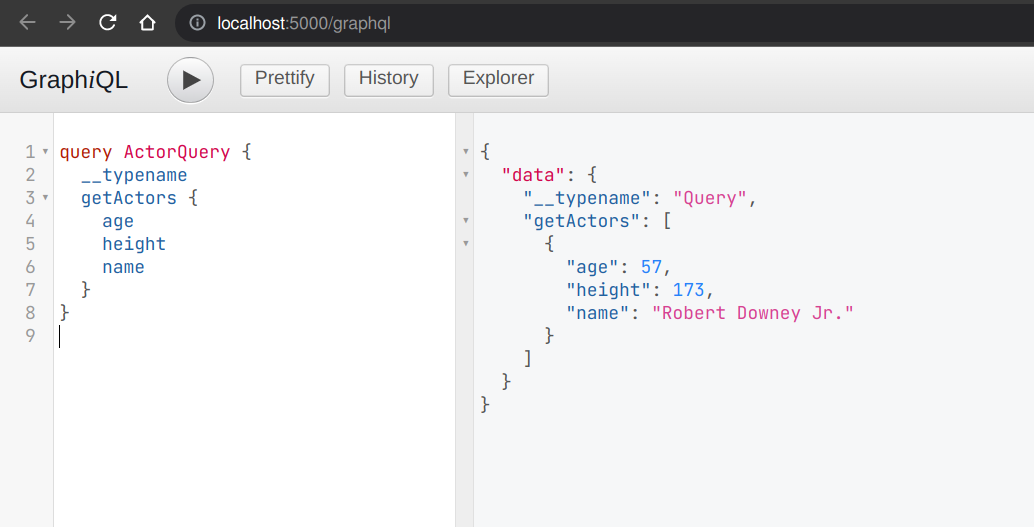
Now that we’ve created an actor object, we can run the previously created query
to fetch the actors. Running the ActorQuery will give you the following
response:
You can also filter actors by their names. To do so, you’d leverage the
filterName parameter of the getActors resolver:
query ActorQuery {
__typename
getActors(filterName: "Robert Downey Jr.") {
age
height
name
}
}This will only display the filtered results. Similarly, as shown above, you can
write the mutations to update and delete actors. Their implementations can be
found in the schema.py file. Check out update_actors and
delete_resolvers to learn more about their implementation details. You can
update one or more attributes of an actor with the following mutation:
mutation ActorMutation {
__typename
updateActors(filterName: "Robert Downey Jr.", age: 60) {
name
age
height
}
}Running this mutation will update the age of Robert Downey Jr.. First,
we filter the objects that we want to mutate via the filterName parameter
and then we update the relevant attributes; in this case, we updated the
age of the object. Finally, we show all the fields in the return payload.
Use the GraphiQL explorer to interactively play with the full API suite.
Query movies
In the schema.py file, the query to fetch movies is constructed as
follows:
# strawberry-gql/app/schema.py
...
@strawberry.type
class Query:
...
@strawberry.field
async def get_movies(
self, filter_name: str | None = None,
) -> list[Movie]:
if filter_name:
movies_json = await client.query_json(
"""
select Movie {name, year, actors: {name, age, height}}
filter .name=<str>$filter_name
""",
filter_name=filter_name,
)
else:
movies_json = await client.query_json(
"""
select Movie {name, year, actors: {name, age, height}}
"""
)
# Deserialize.
movies = json.loads(movies_json)
for idx, movie in enumerate(movies):
actors = [
Actor(name) for d in movie.get("actors", [])
for name in d.values()
]
movies[idx] = Movie(
movie.get("name"),
movie.get("year"), actors
)
return moviesSimilar to the actor query, this also allows you to either fetch all or filter movies by the movie names. Execute the following query to see the movies in the database:
query MovieQuery {
__typename
getMovies {
actors {
age
height
name
}
name
year
}
}This will return an empty list since the database doesn’t contain any movies. In the next section, we’ll create a mutation to create the movies and query them afterward.
Mutate movies
Before running any query to fetch the movies, let’s see how you’d construct a mutation that allows you to create movies. You can build the mutation similar to how we’ve constructed the create actor mutation. It looks like this:
# strawberry-gql/app/schema.py
...
@strawberry.type
class Mutation:
...
@strawberry.mutation
async def create_movie(
self,
name: str,
year: int | None = None,
actor_names: list[str] | None = None,
) -> Movie:
movie_json = await client.query_single_json(
"""
with
name := <str>$name,
year := <optional int16>$year,
actor_names := <optional array<str>>$actor_names,
new_movie := (
insert Movie {
name := name,
year := year,
actors := (
select detached Actor
filter .name in array_unpack(actor_names)
)
}
)
select new_movie {
name,
year,
actors: {name, age, height}
}
""",
name=name,
year=year,
actor_names=actor_names,
)
movie = json.loads(movie_json)
actors = [
Actor(name) for d in movie.get("actors", [])
for name in d.values()]
return Movie(
movie.get("name"),
movie.get("year"),
actors
)You can submit a request to this mutation to create a movie. While creating a
movie, you must provide the name of the movie as it’s a required field. Also,
you can optionally provide the year the movie was released and an array
containing the names of the actors. If the values of the actor_names field
match any existing actor in the database, the above snippet makes sure that the
movie will be linked with the corresponding actors. In the GraphiQL explorer,
run the following mutation to create a movie named Avengers and link the
actor Robert Downey Jr. with the movie:
mutation MovieMutation {
__typename
createMovie(
name: "Avengers",
actorNames: ["Robert Downey Jr."],
year: 2012
) {
actors {
name
}
}
}It’ll return:
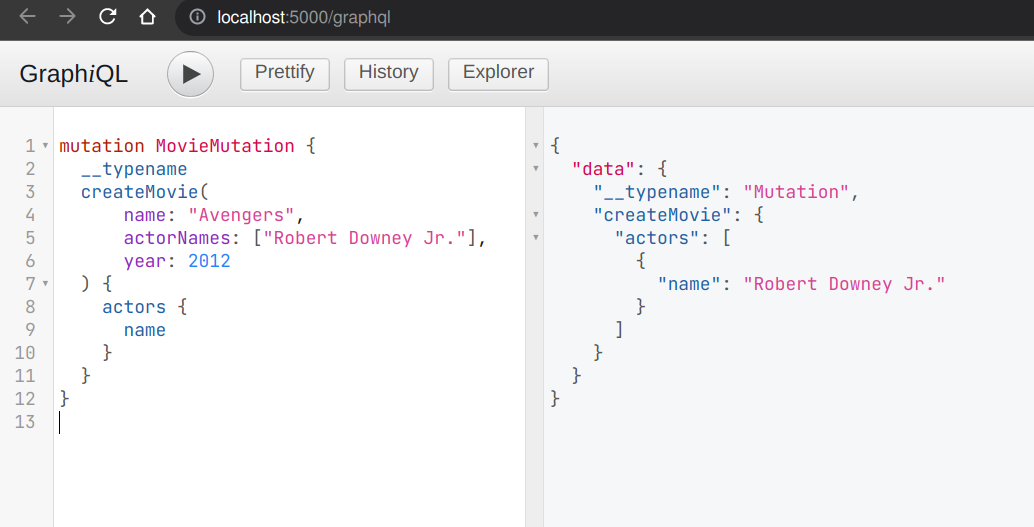
Now you can fetch the movies with a simple query like this one:
query MovieQuery {
__typename
getMovies {
name
year
actors {
name
}
}
}You’ll then see an output similar to this:
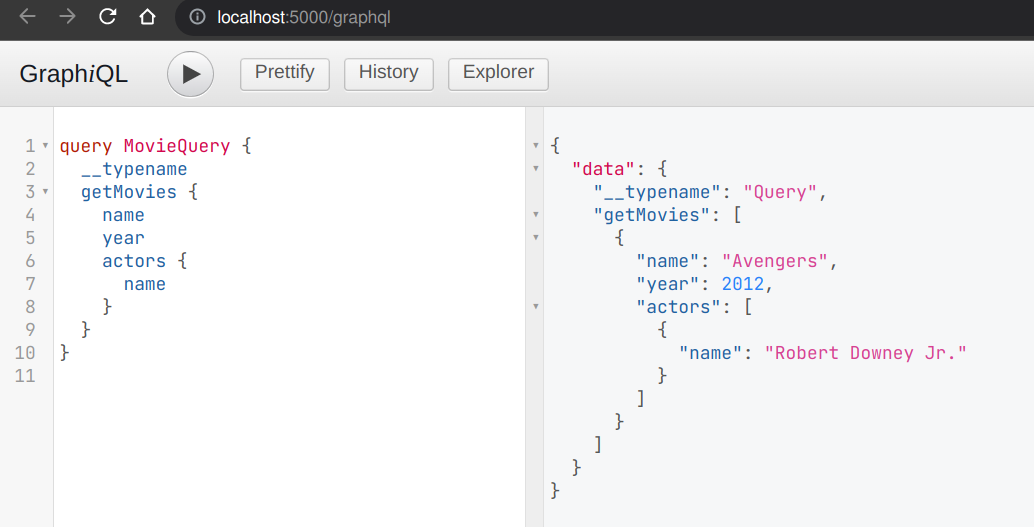
Take a look at the update_movies and delete_movies resolvers to gain
more insights into the implementation details of those mutations.
Conclusion
In this tutorial, you’ve seen how can use Strawberry and EdgeDB together to quickly build a fully-featured GraphQL API. Also, you have seen how FastAPI allows you add an authentication layer and serve the API in a secure manner. One thing to keep in mind here is, ideally, you’d only use GraphQL if you’re interfacing with something that already expects a GraphQL API. Otherwise, EdgeQL is always going to be more powerful and expressive than GraphQL’s query syntax.